Алгоритм ADAM представляет собой эффективный метод стохастической оптимизации, широко используемый в глубоком обучении и машинном обучении.
Adam — это мощный алгоритм оптимизации, который активно применяется в глубоком обучении, в том числе для обучения нейронных сетей, таких как модели LSTM. Адаптивная скорость обучения и коррекция смещения позволяют ему эффективно справляться с различными задачами оптимизации, обеспечивая более быструю сходимость и лучшую производительность по сравнению с традиционными методами.
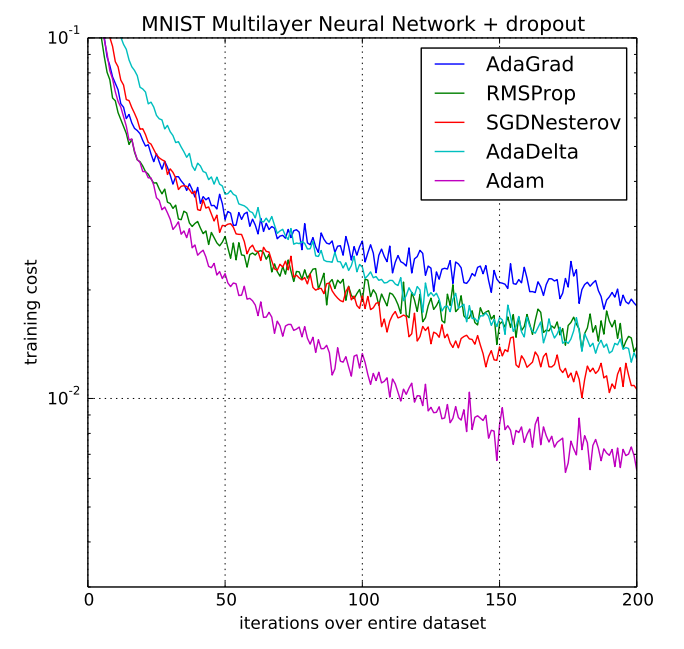 Основные особенности ADAM:
Основные особенности ADAM:
- Простота реализации – алгоритм легко внедряется благодаря своей относительно простой структуре.
- Высокая вычислительная эффективность – ADAM эффективно справляется с задачами даже при ограниченных ресурсах.
- Минимальные требования к памяти – этот метод требует небольшого объема оперативной памяти, что позволяет использовать его в системах с ограниченными ресурсами.
- Подходящий для больших наборов данных и параметров – благодаря своей эффективности, ADAM отлично справляется с оптимизацией сложных моделей, содержащих большое количество параметров и данных.
Алгоритм объединяет два подхода стохастического градиентного спуска:
- AdaGrad (Adaptive Gradient Algorithm) – адаптация градиента на основе накопленных квадратов предыдущих градиентов.
- RMSProp (Root Mean Square Propagation) – нормализация градиенты путем деления их на скользящее среднее квадратов последних обновлений.
Алгоритм наиболее эффективен для решения ряда специфических задач, связанных с обучением нейронных сетей и другими видами машинного обучения. Вот несколько ключевых областей применения, где ADAM демонстрирует свои преимущества:
- Обучение глубоких нейронных сетей: ADAM идеально подходит для задач глубокого обучения, таких как обучение сверточных нейронных сетей (CNN), рекуррентных нейронных сетей (RNN) и других типов архитектур. Эти задачи часто связаны с большими объемами данных и сложностью модели, поэтому высокая производительность и адаптивность ADAM оказываются крайне полезными.
- Оптимизация с шумными данными: Если данные содержат много шума или сильно разбросаны, ADAM может справиться с этой задачей лучше, чем традиционные методы градиентного спуска. Алгоритм устойчив к таким условиям за счет адаптации к изменяющимся характеристикам функции ошибки.
- Нелинейные и негладкие функции: Для задач, где целевая функция имеет сложную структуру (например, негладкая или с локальными минимумами), ADAM помогает избежать застревания в этих минимумах и обеспечивает более стабильное обучение.

- Задачи с неравномерным распределением градиентов: В случаях, когда разные параметры модели имеют различные масштабы изменений, ADAM автоматически адаптируется к этим различиям, корректируя шаги обновления каждого параметра индивидуально.
- Большие наборы данных и сложные модели: ADAM особенно полезен для задач, требующих обработки огромных объемов данных и сложных моделей с множеством параметров. Благодаря своей вычислительной эффективности и минимальному использованию памяти, он позволяет ускорить процесс обучения без потери качества.
- Online Learning: В ситуациях, когда данные поступают постепенно, а модель должна постоянно обновляться, ADAM оказывается эффективным решением, так как он быстро адаптируется к новым данным и изменениям в целевой функции.
- Гиперпараметрическая настройка: ADAM требует меньше гиперпараметров для настройки по сравнению с некоторыми другими методами оптимизации, такими как SGD (Stochastic Gradient Descent). Это упрощает настройку модели и уменьшает риск переобучения.
- Регуляризация и предотвращение переобучения: ADAM включает встроенную регуляризацию, что помогает предотвратить переобучение модели и улучшить ее обобщающую способность.
Источники
1. https://arxiv.org/abs/1412.6980v9
2. https://blog.marketmuse.com/glossary/adaptive-moment-estimation-adam-definition/
